“O horror! O horror!”
Suponha que você precise estimar uma semelhança entre dois ou mais documentos.
Uma abordagem comum é extrair recursos de cada documento na forma de um vetor de bits e, em seguida, usar a similaridade de cosseno para obter um valor entre 1 (igual) e 0 (completamente diferente).
Agora, é tudo diversão e jogos até você ver isto:
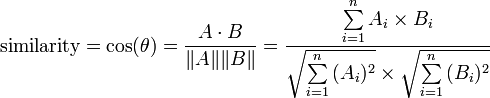
Não entre em pânico (ainda); e se eu dissesse que a função acima pode ser implementada com no máximo 10 linhas, em Perl?
sub cosine_similarity {
my ($a, $b) = @_;
my $nbits_a = unpack(q(%32b*) => $a);
my $nbits_b = unpack(q(%32b*) => $b);
return $nbits_a * $nbits_b
? unpack(q(%32b*) => $a & $b) / sqrt $nbits_a * $nbits_b
: 0;
}Bem, pelo menos, enquanto você se limita ao vetor de bits . Não há atalhos se você usar um hash com contagem de palavras em vez do sinalizador de palavra presente / ausente. Mas, ei, essa é a única informação disponível em muitas tarefas de filtragem colaborativa , de qualquer maneira: muitos usuários marcam itens imediatamente como seus favoritos, apesar de não quererem dizer o quanto eles gostam.
Então, qual é o truque?
Pense em booleano. Multiplicação ( *) é apenas um bit a bit e ( &). Assim, = = = . E que tal isso ? Para um vetor de bits, é uma contagem de bits diferentes de zero, conhecida como peso de Hamming (também, contagem de população , contagem de pop ou soma lateral ). Você poderia simplesmente percorrer o vetor de bits para fazer isso:A²A * A$a & $a$a∑
$count += vec($str, $_, 1) for 0 .. 8 * length $str;… mas é exatamente para isso que a soma de verificação unpack () se destina! Você só precisa especificar a largura de bits do valor da soma de verificação (32 é o suficiente).
E, é claro, não há necessidade de computar nada se um dos vetores de bits estiver completamente vazio.
Juntando tudo
Voltando ao problema original: vamos estimar a semelhança entre dois documentos. Esperar até 8.192 recursos exclusivos parece ser justo, de acordo com meus testes:
#!/usr/bin/env perl
use common::sense;
use File::Slurp;
use Text::SpeedyFx;
my $sfx = Text::SpeedyFx->new;
say cosine_similarity(map {
$sfx->hash_fv('' . read_file($_), 8192)
} qw(document1.txt document2.txt));Por exemplo, a similaridade entre os arquivos README.freebsd e README.openbsd da versão Perl v5.16.2 é de aproximadamente 0,64, que é maior do que entre README.freebsd e README.linux (aproximadamente 0,47).