Como os engenheiros e o pessoal de operações de servidor sabem, os melhores sistemas são aqueles que permitem que você durma à noite. Quando há problemas, grandes sistemas contatam os engenheiros com as informações certas nos momentos certos.
Depois de 13 anos criando aplicativos da web, reduzi minhas idéias sobre o monitoramento de seus sistemas às seguintes oito estratégias:
Inscreva-se no Pingdom . Use-o para solicitar a página inicial do seu site e para verificar se há uma palavra esperada em algum lugar do corpo do HTML. No RockThePost , configurei-o para garantir que a frase “Investimento em startups” seja encontrada. Se o Pingdom não encontrar isso, ele entrará em contato comigo. Eu sei que algo está muito errado se Pingdom ligar e eu me afastar do jantar para investigar. Este é o catch-all mais fácil que você pode configurar.
Use monitoramento ambiental como CloudWatch ou New Relic . Construímos RockThePost com RightScale, que já tem toneladas de monitoramento. Fomos capazes de monitorar automaticamente todos os recursos internos do servidor por padrão, como CPU, consumo de memória, espaço em disco, solicitações do Apache, atividade do MySQL e muito mais. Se você está na Amazon, você pode querer dar uma olhada no CloudWatch. Se você não está na Amazon, dê uma olhada no New Relic.
Registre erros e outras informações valiosas sobre eventos em seu aplicativo. Mesmo que seu site esteja retornando páginas iniciais corretamente e o ambiente do servidor seja saudável, seu aplicativo pode estar quebrado. Você precisa instituir um manipulador de exceção de aplicativo em seu código que registra os detalhes da exceção em um arquivo de log no sistema de arquivos. Minha maneira favorita de registrar coisas é agrupar todas as informações de exceção, as informações do servidor (endereço IP, nome do servidor) e qualquer informação de código relevante, como tag atualmente implantada, em uma string JSON e, em seguida, registrar tudo em apenas uma linha . A razão para fazer isso faz sentido mais tarde.
Pouco antes de carregar o meu manipulador de exceções, também gosto de gerar um uniqid. Eu escrevo essa id exclusiva na entrada de log JSON, mas também exibo o uniqid desse erro específico para o usuário na página de erro / desculpas amigável “Desculpe”. Dessa forma, se alguém entrar em contato com você posteriormente, poderá dizer “O recurso X não funcionou e aqui está o id de erro que recebi”. Agora, você tem uma maneira fácil de descobrir o que deu errado.
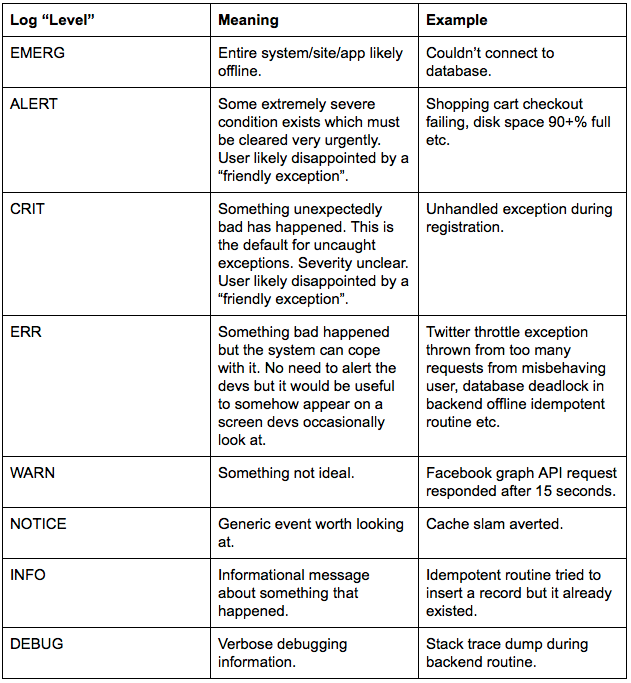
- Categorize o quão ruins são os erros e / ou entradas de registro. Você deseja utilizar uma convenção para categorizar o quão ruim é uma exceção ao registrar. Por padrão, eu registro minhas exceções como CRIT, o que significa que algo totalmente inesperado aconteceu e alguém provavelmente ficou desapontado. Se o problema não for tão grave, registrarei um erro de nível de ERR. Para erros mais graves, registrarei os erros de nível de EMERG e ALERTA. Aqui está um guia geral sobre o significado que atribuímos a cada um dos níveis de erro de registro:
Consolide todos os seus registros com PaperTrailApp . O maior problema com o armazenamento de arquivos de log em um servidor é que eles estão presos nesse servidor. Você deseja ser capaz de consolidar todos os logs em uma única interface com uma maneira inteligente de filtrar por ela. Minha solução favorita para isso é PaperTrail. É um aplicativo da web que me dá uma única rolagem online ao vivo da consolidação de todos os logs em todos os meus servidores. Se alguém obtiver uma exceção, os detalhes aparecem imediatamente na interface do PaperTrail. Em nosso escritório, contamos com uma grande tv de tela plana que gira em diferentes telas de informação. O registro de eventos do PaperTrail está em uma das telas pelas quais giramos.
Inscreva-se no PagerDuty para ser contatado sobre problemas em seu sistema. O PagerDuty permite que você defina quem está “de plantão”. Mesmo se você tiver apenas um desenvolvedor que lida com tudo, o PagerDuty pode pegar uma mensagem e entregá-la ao engenheiro de plantão em um smartmaneira. Em vez de enviar mensagens repetidamente a uma pessoa sempre que um erro é recebido, o PagerDuty sabe como eliminar a duplicação de um problema e apenas tentar contatar uma pessoa por meio de um agendamento personalizável de maneira ordenada. Minha conta do PagerDuty está configurada para enviar um e-mail, esperar 5 minutos, enviar uma mensagem de texto, esperar 5 minutos e ligar para o meu telefone. Se meu telefone tocar, uma voz robótica que soa como Stephen Hawking lê a visão geral da exceção para mim. Tenho que limpar o problema e marcá-lo como “resolvido”. Eles até têm um aplicativo móvel.
Crie convenções e estratégias inteligentes para responder aos seus erros. PaperTrail oferece a capacidade de definir pesquisas salvas e, em seguida, colocá-las no PagerDuty. Por exemplo, envio os erros CRIT, EMERG e ALERT para mim por meio do PagerDuty. Ignoro o nível de ERR e reduzo os problemas. Este é o link mágico que permite que uma exceção lançada no ambiente ativo seja enviada diretamente ao desenvolvedor por meio de sua estratégia de contato preferida. É uma boa ideia enviar os problemas de gravidade ALERT e EMERG para um serviço PagerDuty especial que usa uma política de contato mais agressiva, de modo que os desenvolvedores sejam contatados mais rapidamente.
Exiba uma página de erro amigável útil “ops, desculpe” com um formulário de tíquete de suporte ZenDesk . Nossa página ops pede desculpas pelo incômodo, mostra ao usuário o número de identificação do erro, permite que ele registre um tíquete de suporte via ZenDesk e exibe uma lista de empreendimentos apenas para que ainda haja algo um pouco relevante para olhar.
Essa estratégia para lidar com exceções é o que eu recomendaria na maioria dos casos para uma equipe de pequeno a médio porte. Depois de instituí-lo, você pode refinar e ajustar as coisas à medida que avança. Se você corrigir metodicamente os erros que surgem e ajustar seus logs para ignorar erros sem importância, você se verá em uma situação em que os piores erros são eliminados e a estabilidade do seu sistema é maior do que antes.